
Sounds & Models
–
Sounds & Models –
Project
Interactive Demo
Role
UX/UI Designer
Agency
Sparks
Timeline
10 Weeks (Part Time)


“Sounds & Models” was one of many interactive demos that Sparks created for Google Cloud, for their annual “Google Next” conference at Moscone Center in San Francisco.
The
Problem
Showcase the power of Google’s Machine Learning SaaS products in a fun, engaging, and digestible interactive experience.
The final solution was a three sided installation showcasing the different phases of creating and utilizing a machine learning model.

The Process
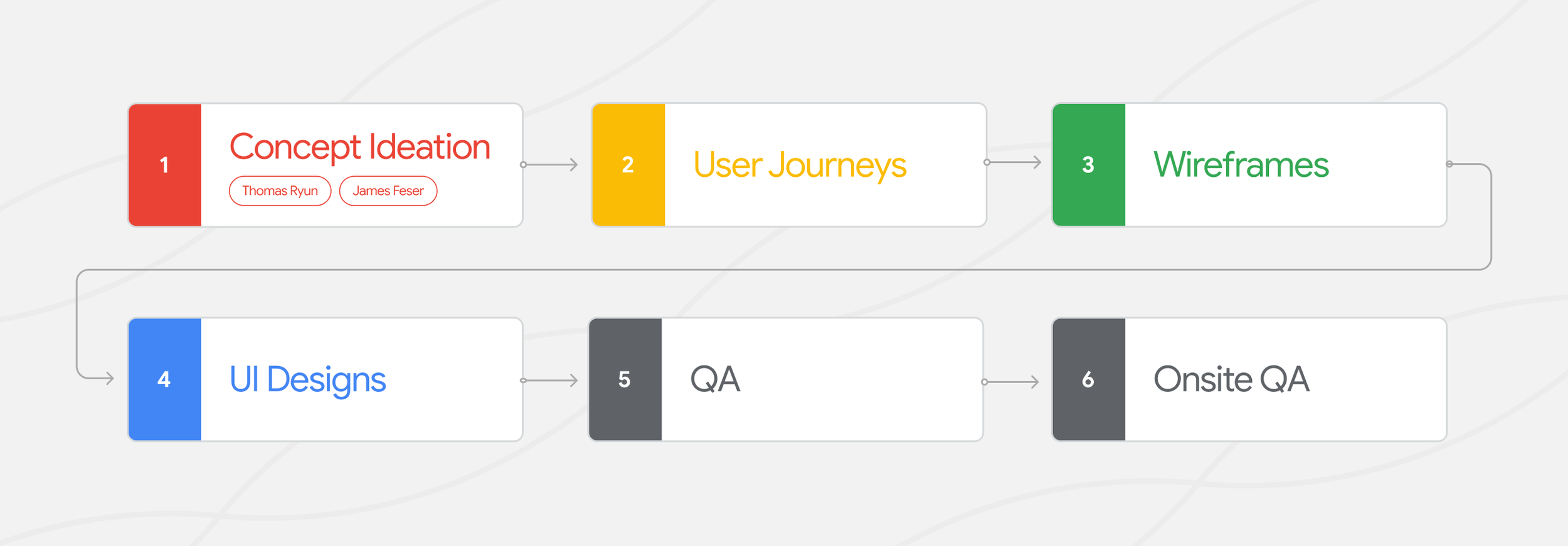
User Journeys


Wireframes
The Final Solution
Phase 1 – Gather Data
In the first phase, users would pluck virtual strings on a monitor. After the string was plucked, the soundwave would appear in the queue on the right screen, and would be converted in real time into a spectrogram.
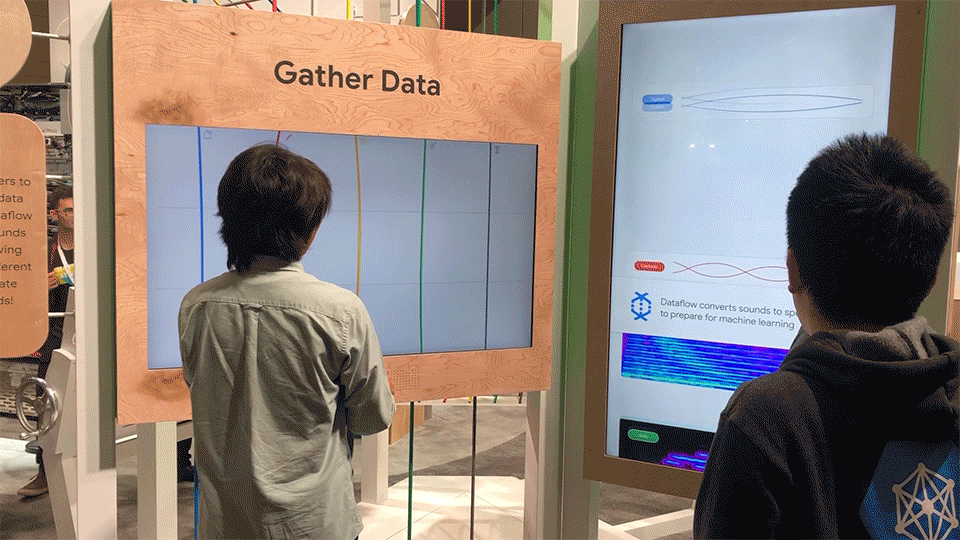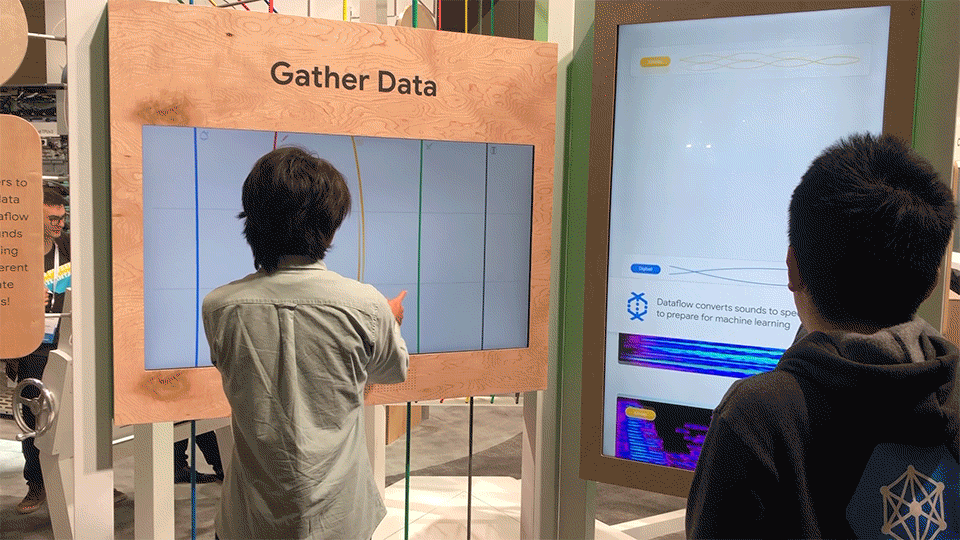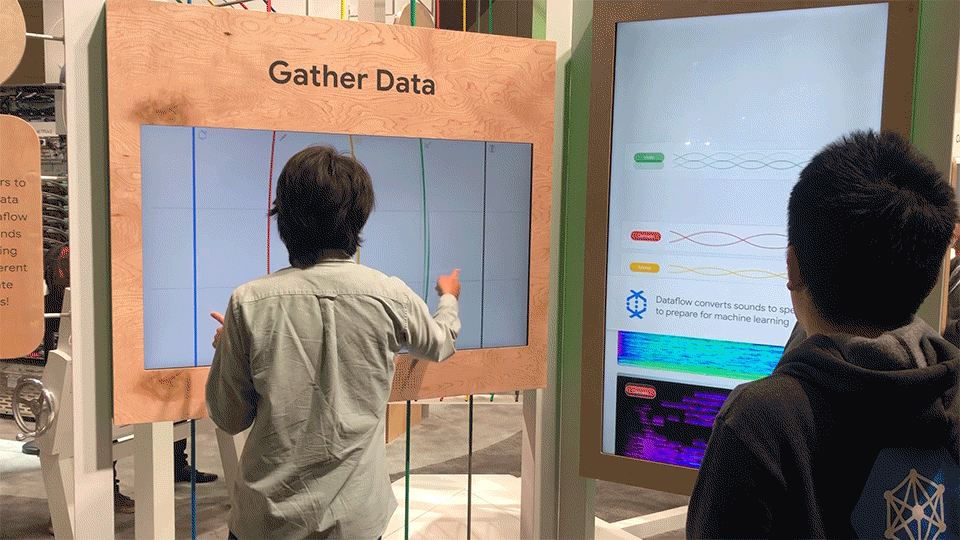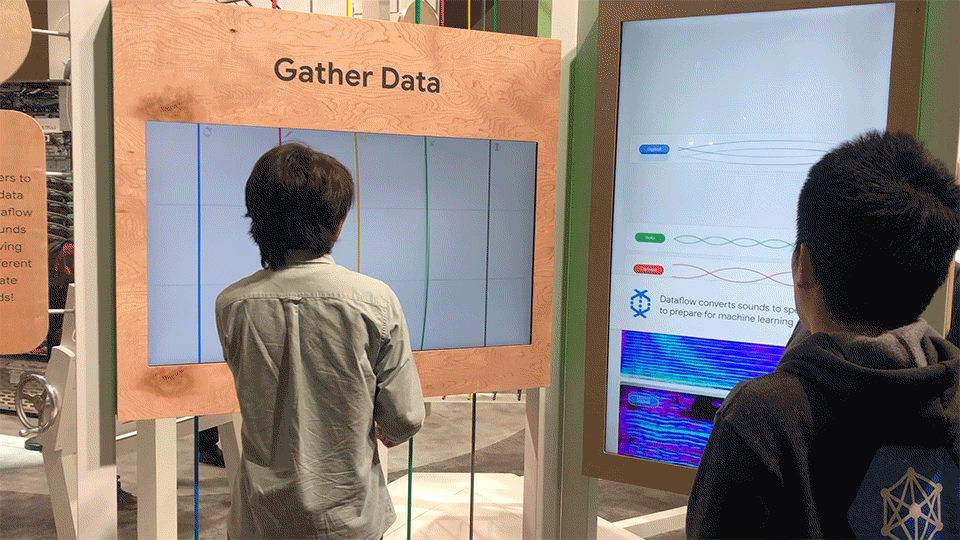

The instrument interface allowed users to pluck strings, which correlated to different instruments. The interface included metaphorical fretboards, allowing for subtleties in sound based on the y value of the pluck.

The queue screen consisted of an empty state, queued state, and output state.
Phase 2 – Train Models
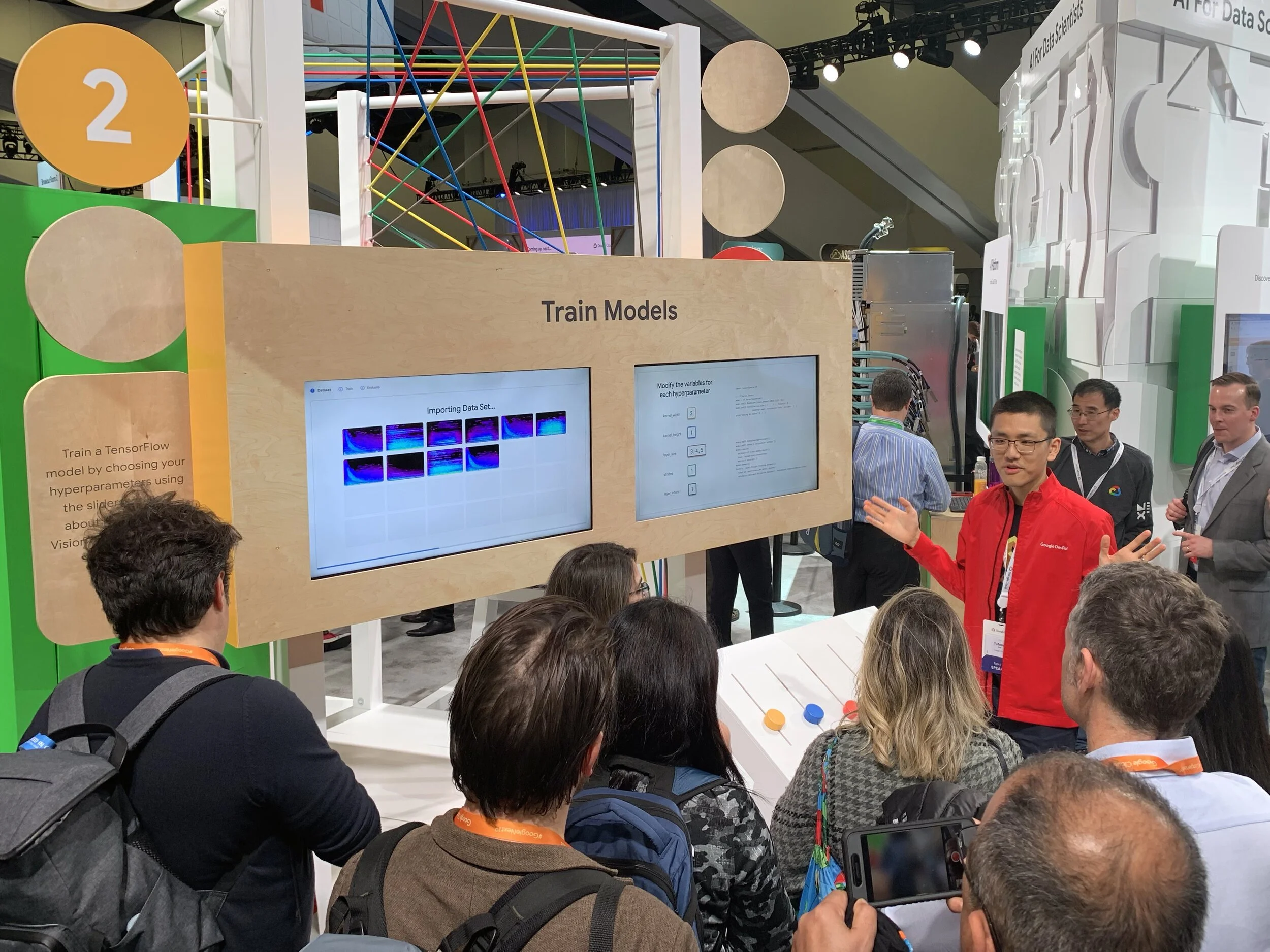
In the second phase, the users viewed the left screen to watch as the spectrograms were imported, trained, and evaluated.
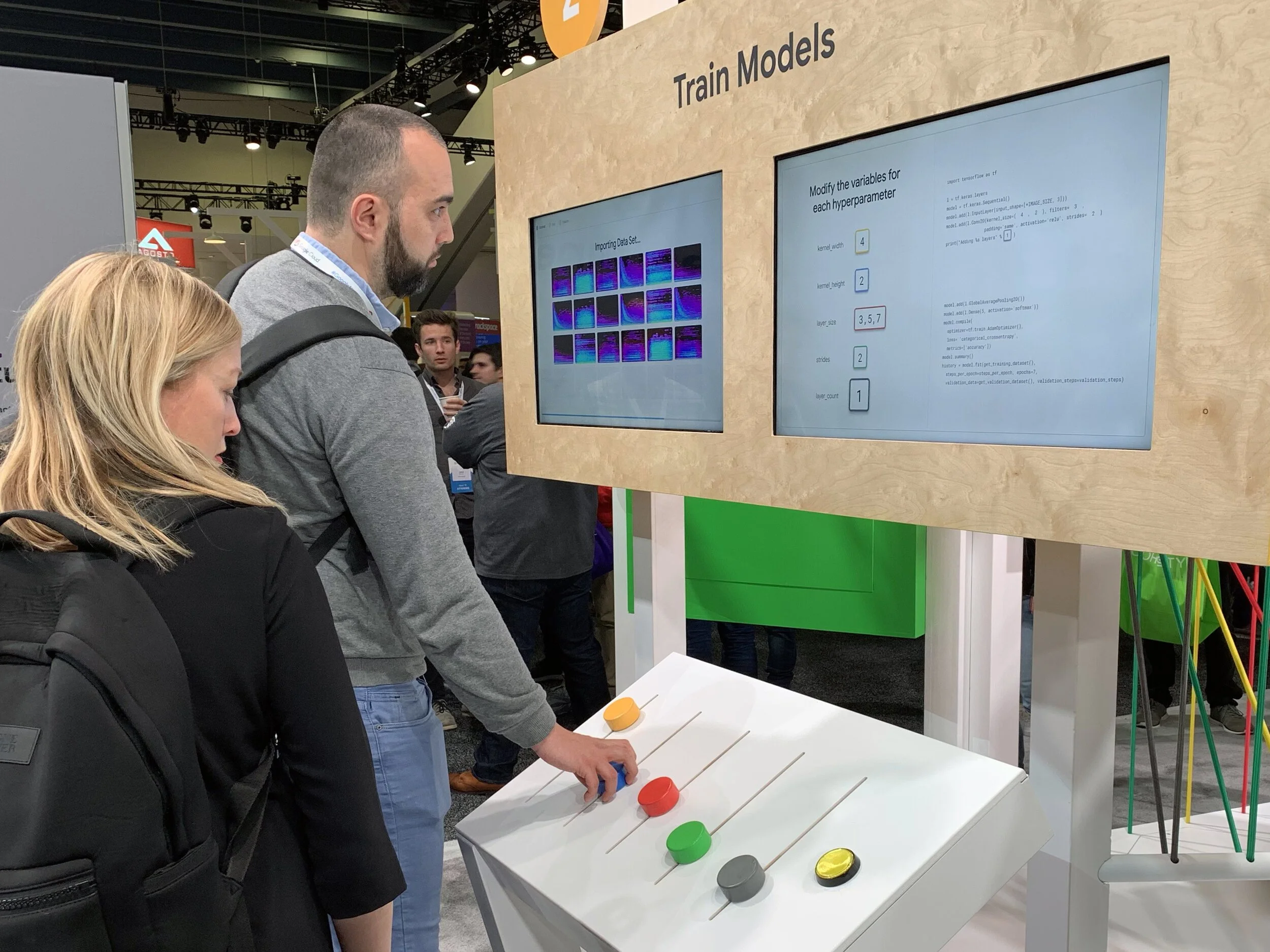
On the right screen, the users had the option to manually modify the hyperparameters for their model. This interaction was simplified into a set of playful sliders that correlated to variables on the screen.
After the user submitted their variables, their custom configuration was shown moving through the different Google Cloud services.
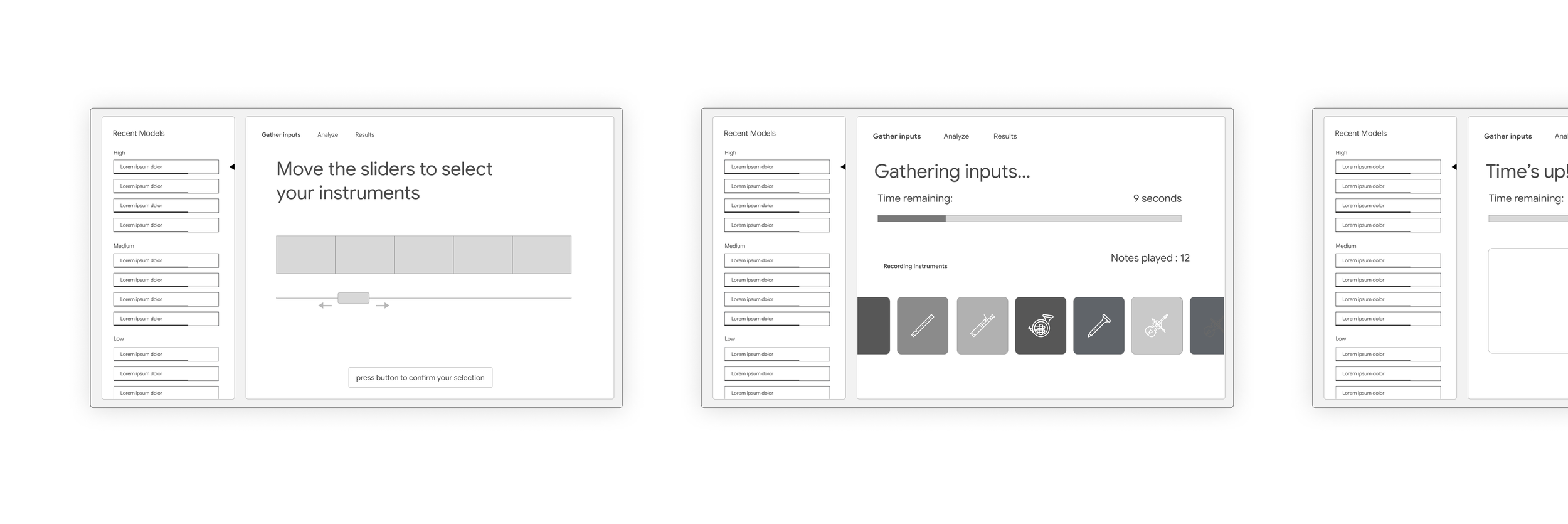
Phase 3 – Predict Notes

In the third phase, user’s started by selecting their model using a physical crank. Next, they were able to “compose” a short symphony. The user adjusted physical sliders correlating to specific instruments, then turned the crank to generate their symphony.

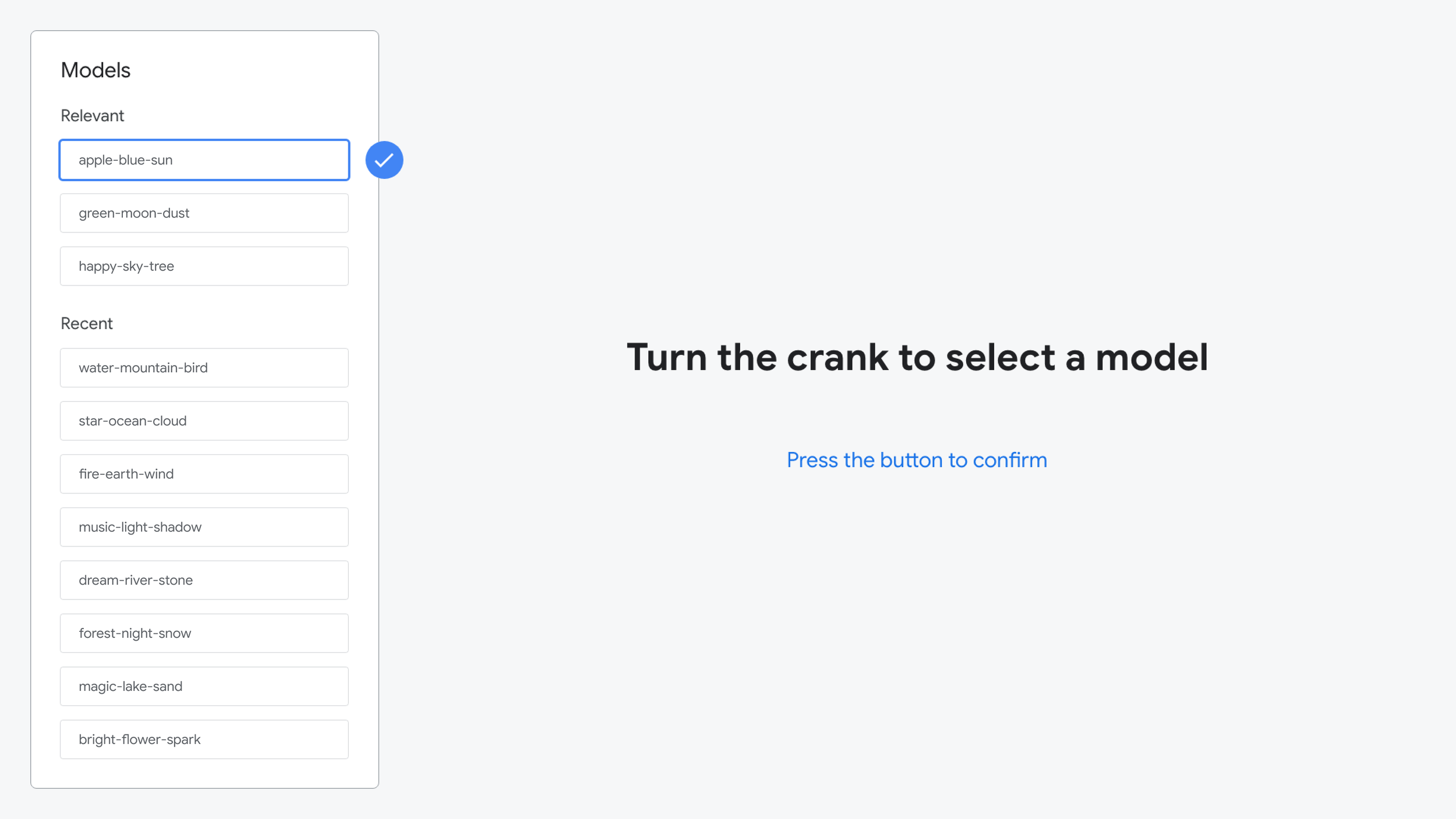
Model selection using the physical hand crank
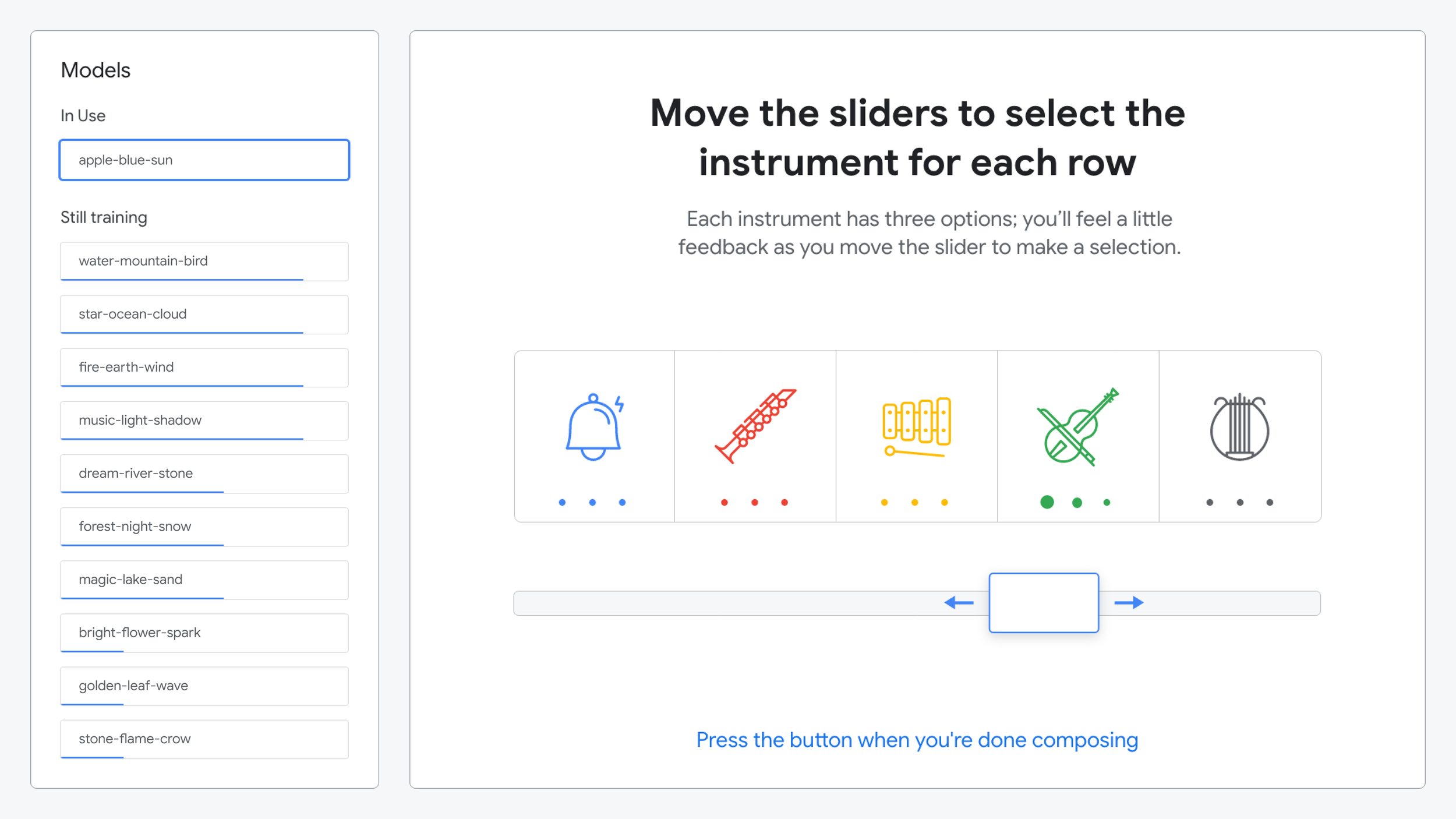
Instructions for composing their symphony

Animation shown on instructions screen
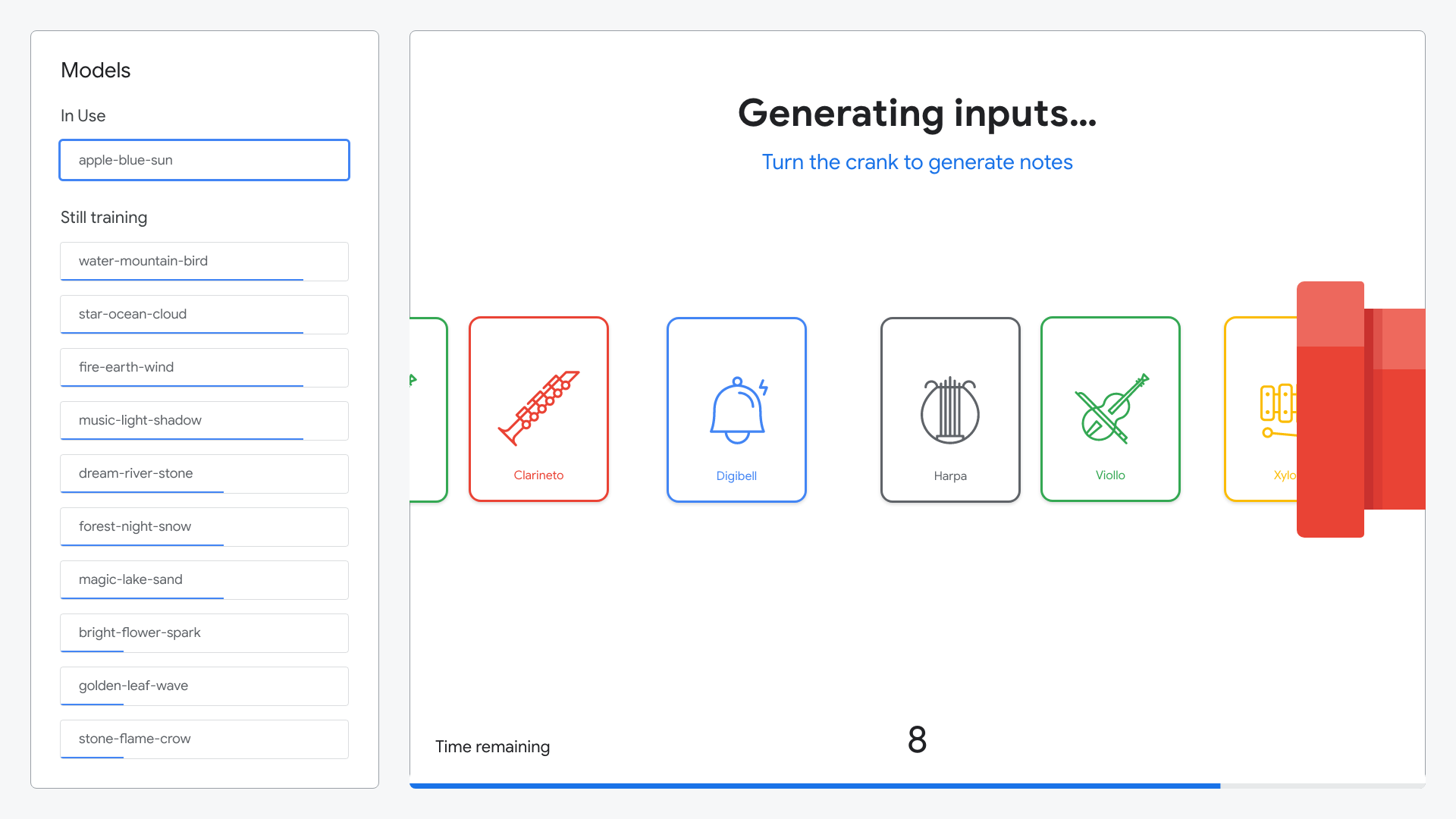
As the user turns the crank, their symphony is generated.

After composing their symphony, the ML model would analyze all of the sounds they created and generate predictions as to what each sound represented.
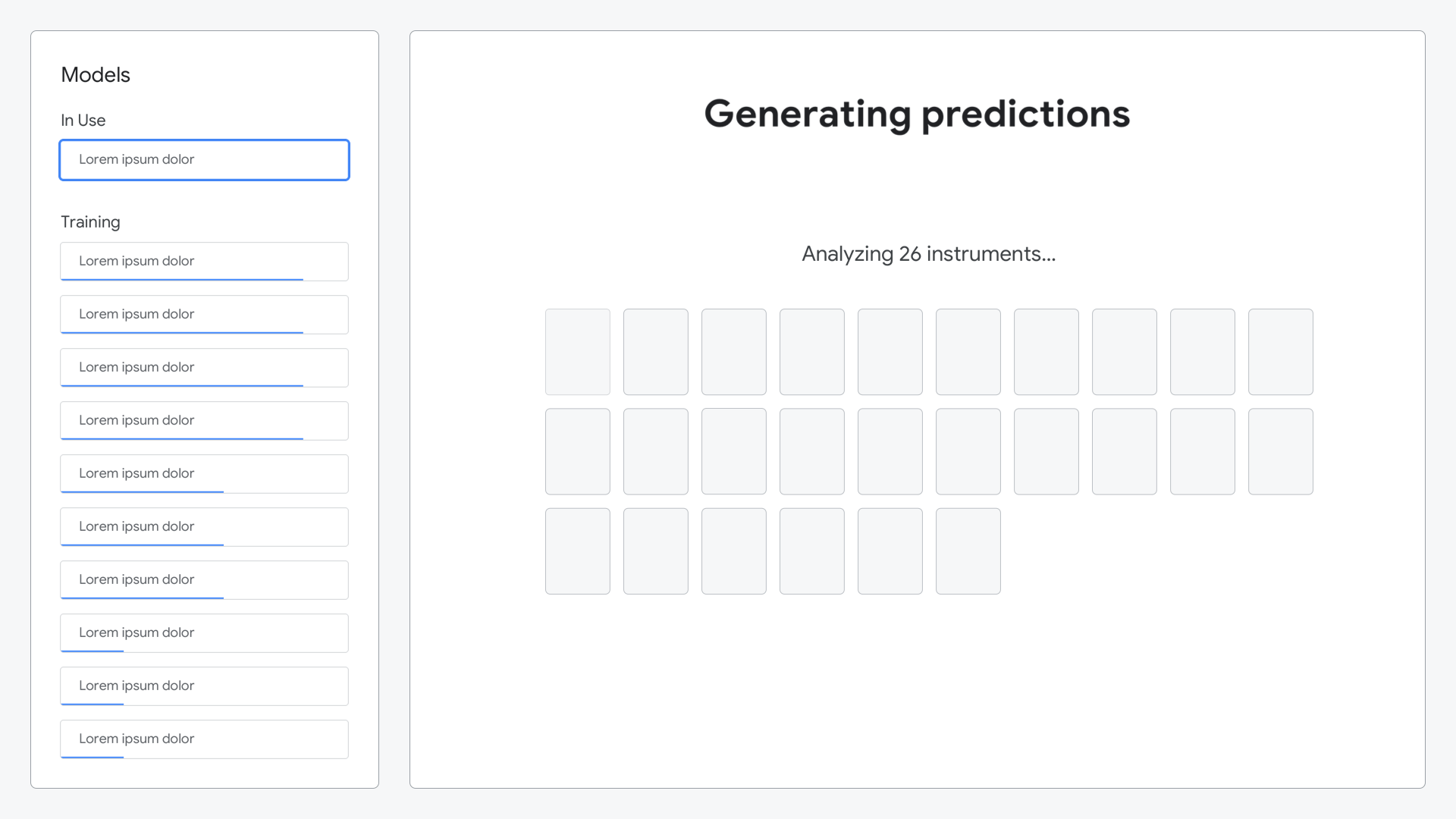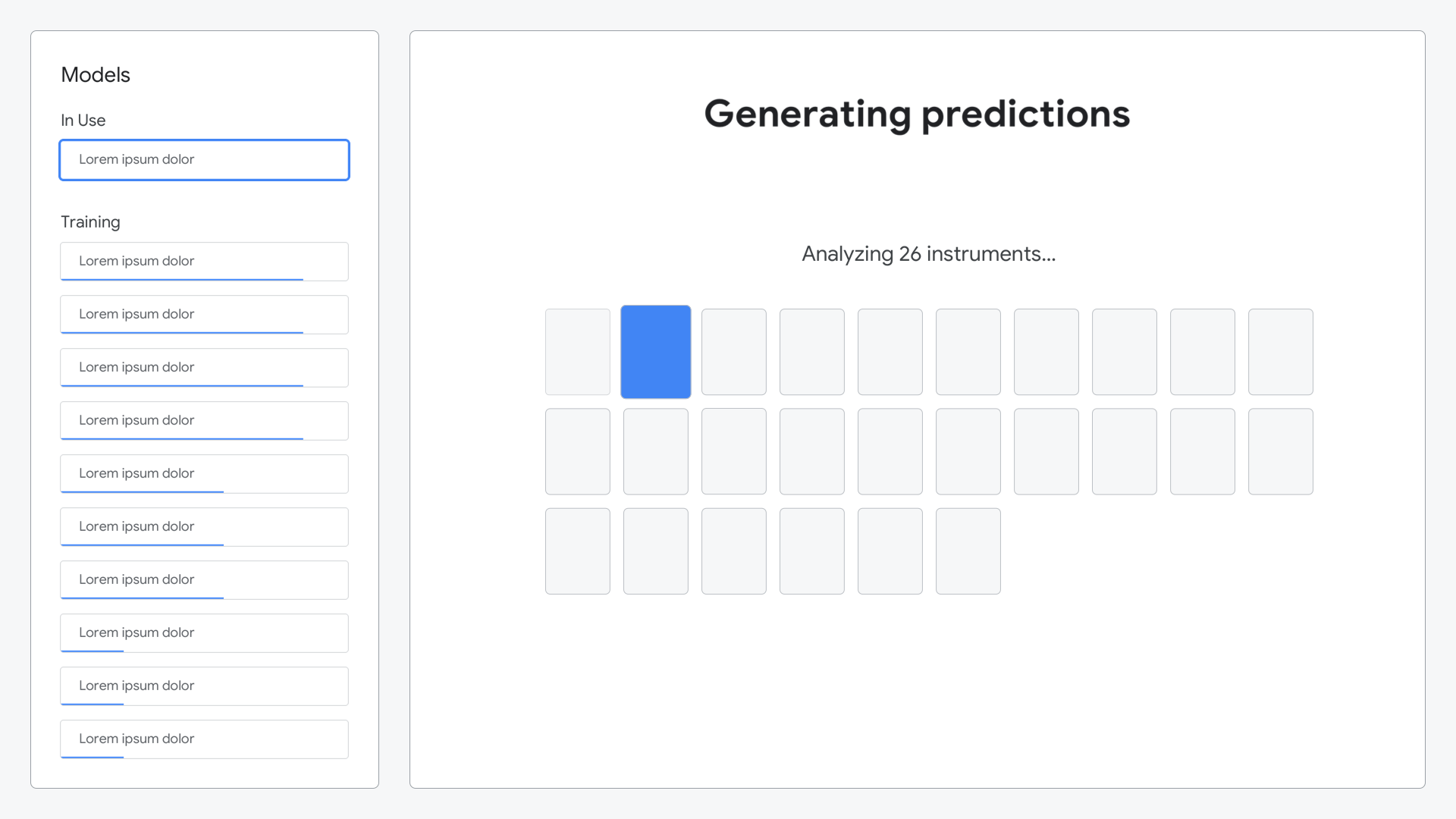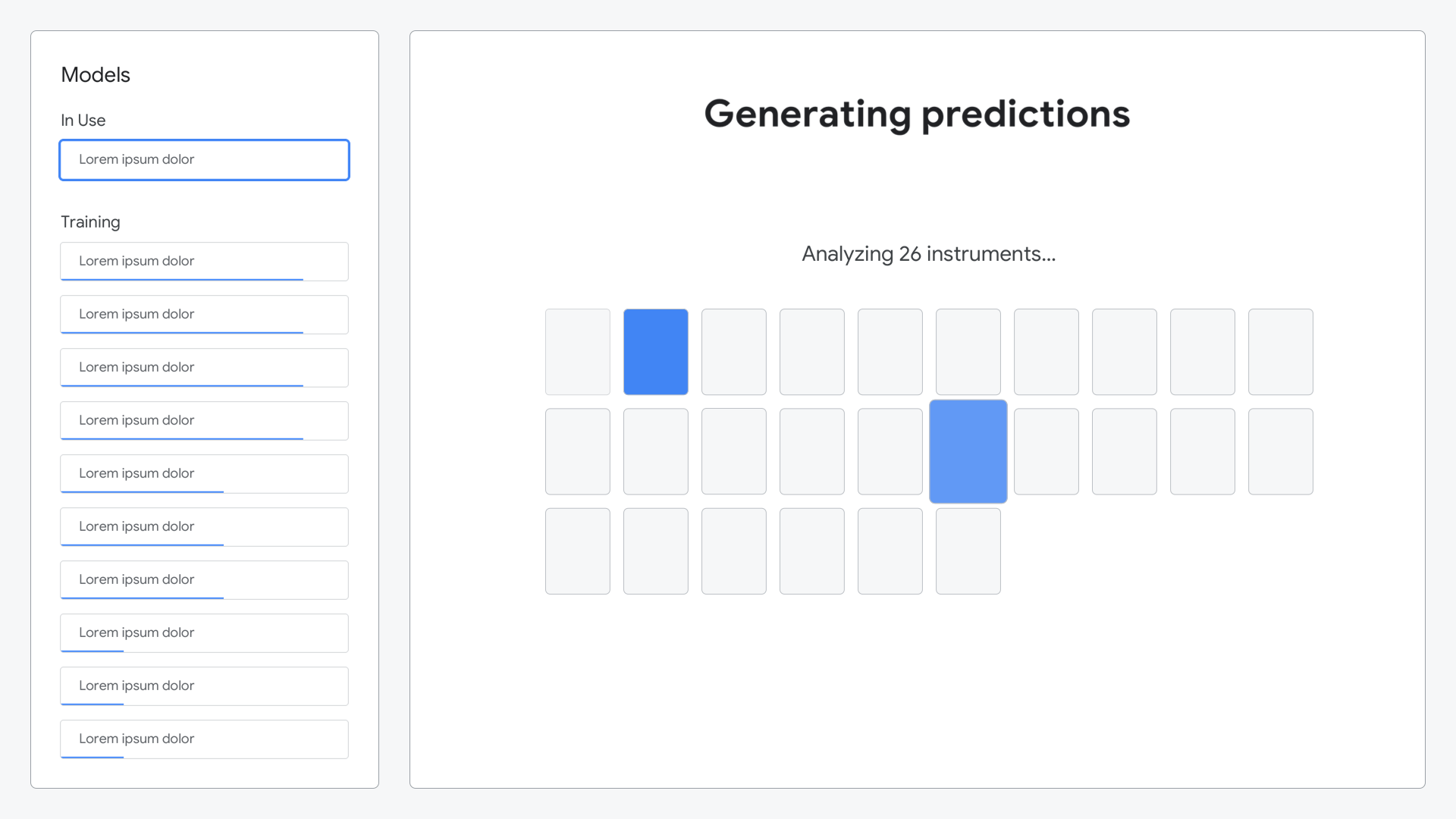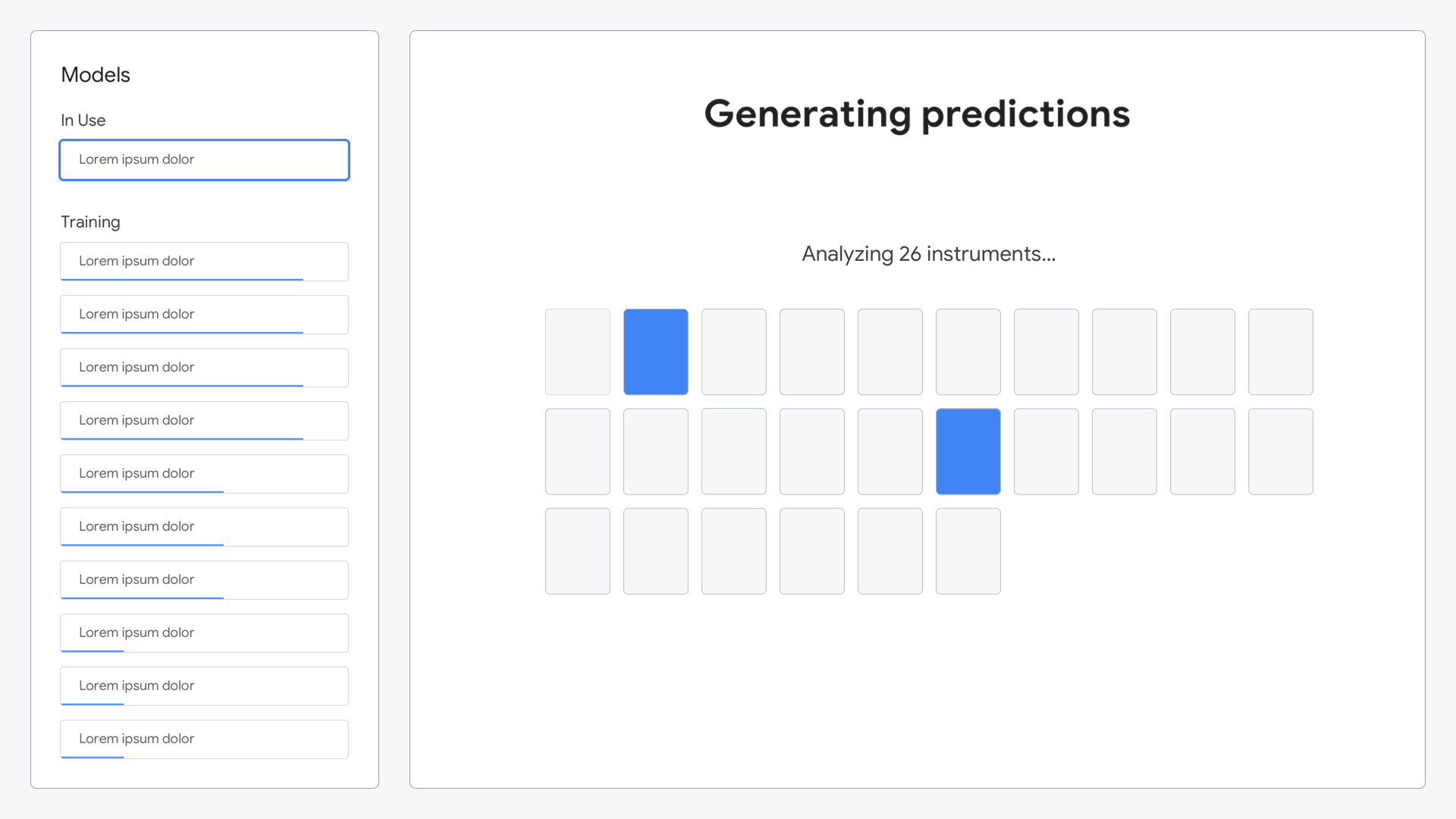
Animation shown while the model was generating its predictions
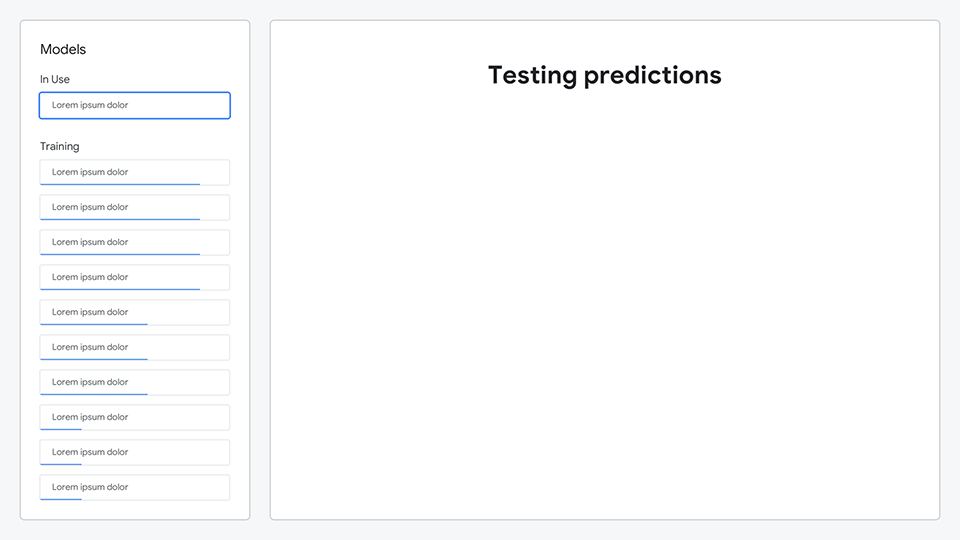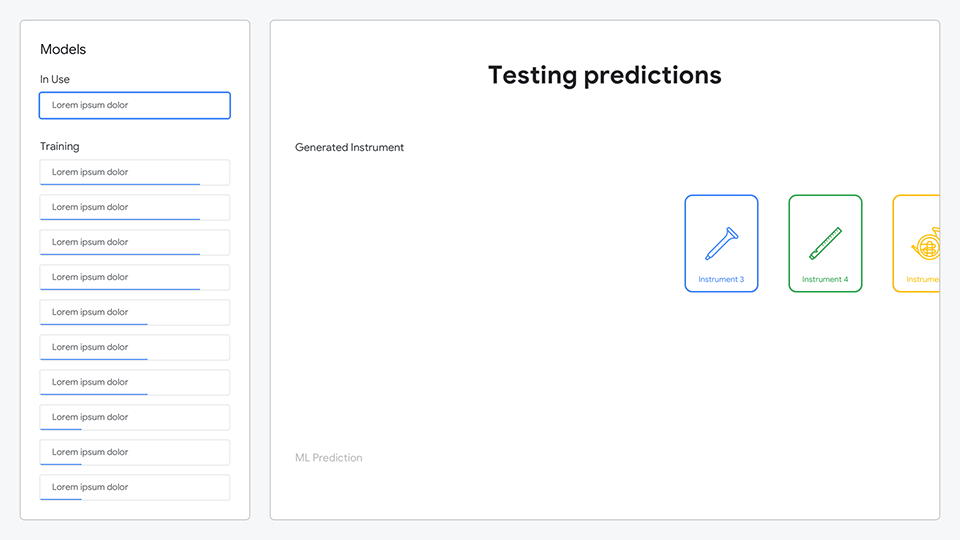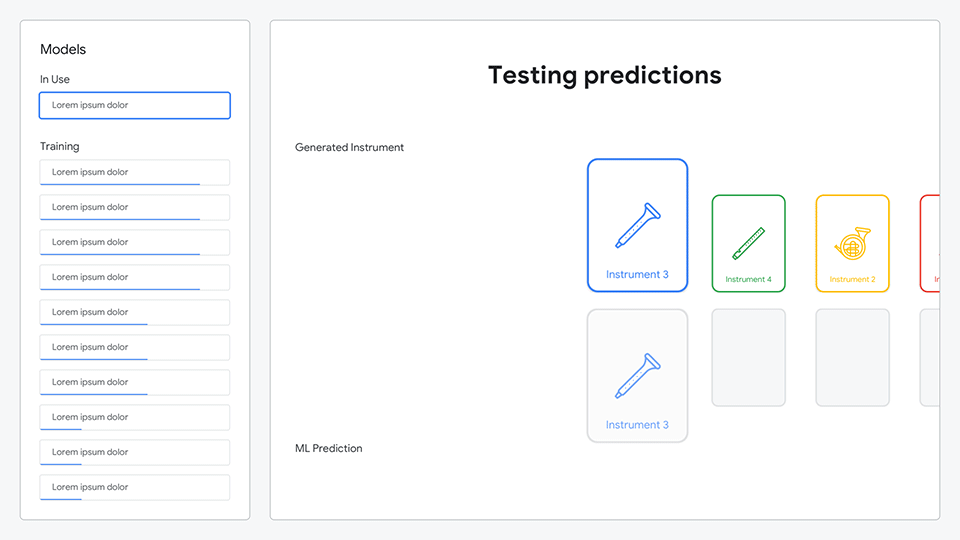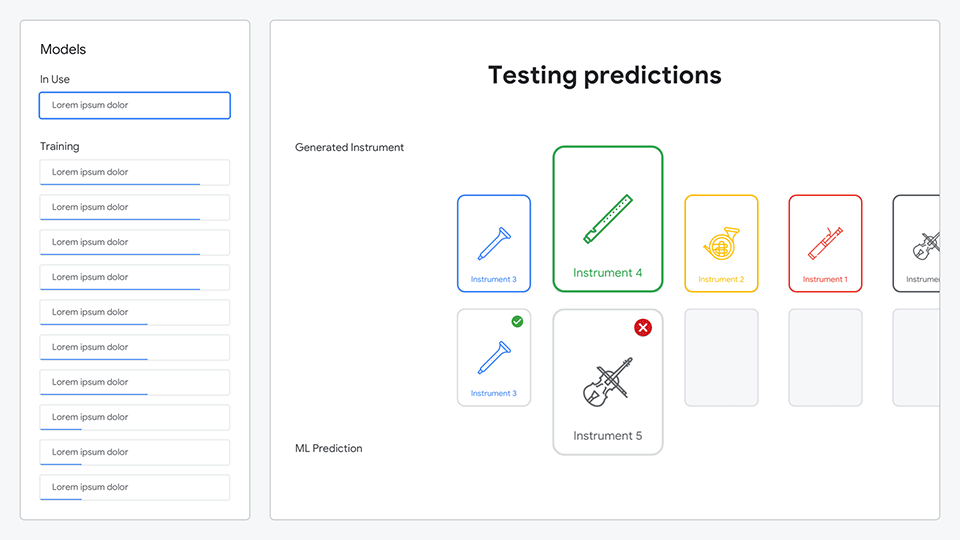
Animation comparing the generated instrument to the ML prediction
Want to learn more? Watch the full walkthrough of the demo.
Credits
Jai Sayaka, Digital Producer
James Feser, Creative Director (3D)
Mike Roth, Designer (3D)
Tyler Adamson, Event Manager
Jamie Barlow, SVP Creative Technology
Thomas Ryun, Creative Director (Interactive)
Marcus Guttenplan, Senior Creative Technologist
Justin Lui, Creative Technologist